

In the hub article about my AI content system, I mentioned something called the pitch generator and moved on pretty quickly. I want to slow down here because it's the most counter-intuitive part of the whole setup — and honestly, the part I'm most glad I got wrong first before getting right.
Here's the short version: every morning at 6:35 AM, a script called propose-topics.js writes a list of content pitches to a queue file. Subject, one-line reason why now, a rough priority rating, seed URLs. That's it. Nothing gets researched. Nothing gets drafted. The system just asks what I want to work on and then waits.
That might sound obvious. It wasn't how I started.
What the system was doing before
The original version of this pipeline was more aggressive. It would pick topics on its own and auto-draft them overnight. I'd wake up to finished articles sitting in a folder, ready to publish.
That sounds great. In practice it was kind of a mess.
The problem wasn't that the drafts were bad, exactly. It's that I hadn't agreed to any of them. I'd open my laptop and find 1,200 words on a topic I had no context for, no opinion on, and no memory of deciding to care about. Some mornings the drafts were genuinely interesting and I'd think "okay, sure, I'll work with this." Other mornings I'd close the tab immediately and feel vaguely annoyed at my own system.
The darker version of this: at one point an earlier inspiration path produced a pitch built on fabricated research about a creator I didn't actually know. The system had invented a story and written it up confidently. That one shook me a little. Not because AI hallucinated — that's a known thing — but because the auto-draft architecture meant the hallucination got all the way to a finished piece before I ever touched it.
That's when I understood the real problem. The bottleneck wasn't topic quality. It was that the decision about what to make was happening without me.
The ideas-first pivot
The fix shipped on June 7th and I've been calling it the ideas-first pivot internally. The logic is simple: the system earns the right to draft by asking first.
Now propose-topics.js generates pitches, not drafts. I approve one (either through the Command Center interface or just by telling Sherman in chat), and then research and drafting happen. The decision stays with me. The system does the legwork of surfacing options and making a case for each one — but it doesn't move until I say go.
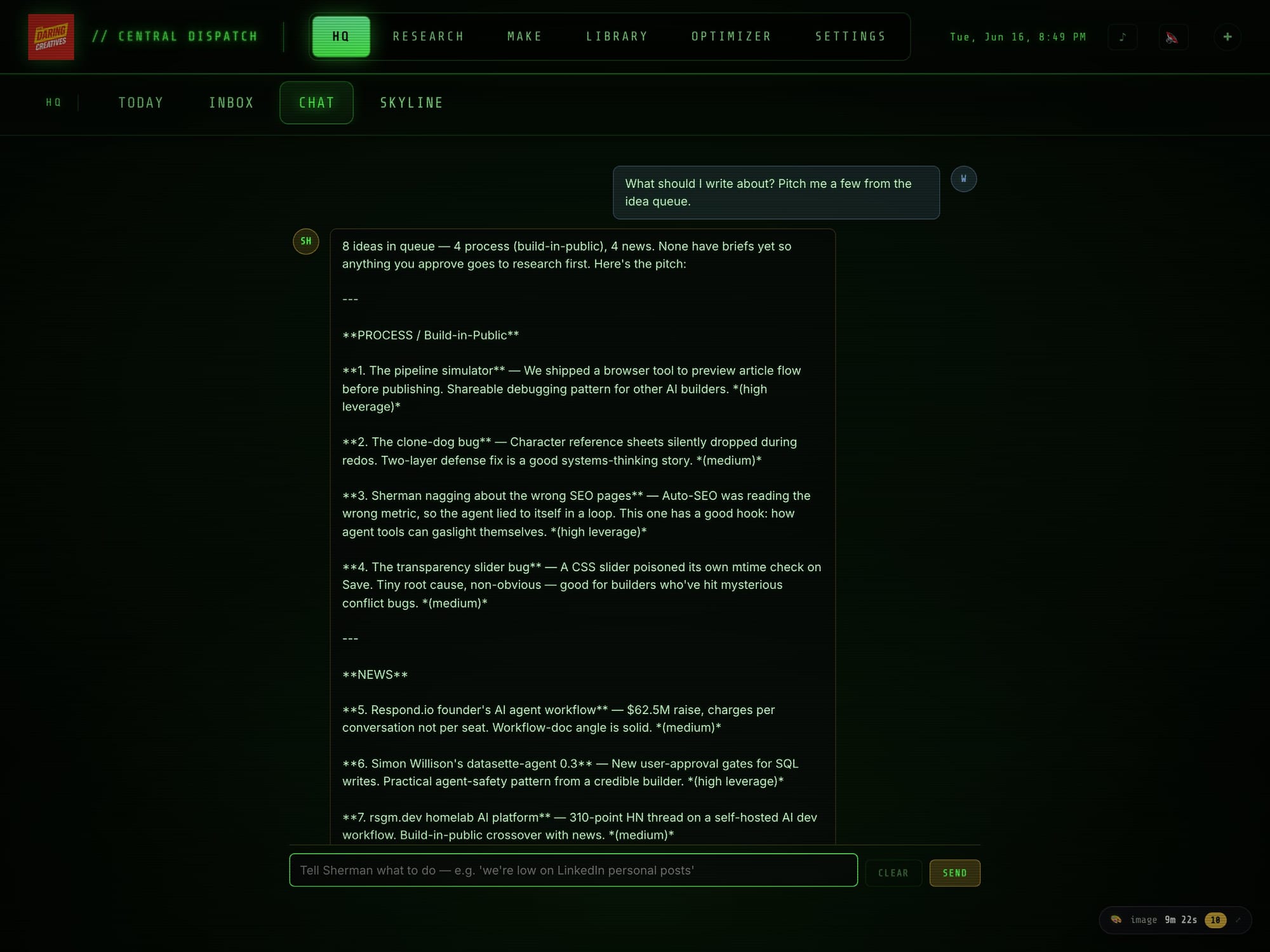
This is a small architectural change. It's also the difference between a system I trust and one I'm constantly second-guessing.
What signals the pitch generator actually reads
This is the part I find genuinely interesting to explain, because it's not just "scan the news and pick something trending."
The system reads three sources when building each morning's pitch queue.
The first is the AI news feed — a rolling ~14-day window of tagged headlines and developments that gets updated automatically. This is the obvious one. Something ships, something gets announced, the system notices and asks whether we should write about it.
The second is what I call the striking-distance report — a Search Console analysis of queries where this site already ranks somewhere between position 4 and 20. These are terms where we're getting impressions but not many clicks. We're close to page one but not quite there. A well-timed piece that actually addresses the query directly could push one of those rankings over. The pitch generator uses this as a signal for what's worth doubling down on, not just what's new.
The third source is the build journal — a log of decisions, git commits, and session activity that tracks how the system itself was built. This is where the "build in public" pitches come from. When I've spent a week solving a specific problem in the pipeline, the journal knows that happened. The pitch generator can look at recent activity and say, essentially, "you just figured something out — should we write about it?"
The mix is intentionally around 50% build-in-public content and 50% news-driven. In my experience, the process pieces perform better over time. Hot takes have a short shelf life. "Here's how I built this specific thing and what broke" tends to keep pulling traffic for months.
How it defends against repeating itself
One thing I didn't want was a system that pitches the same dead ideas every morning. If I reject something, I want it gone, not cycling back into the queue next week with slightly different wording.
So rejected pitches get blacklisted. When I pass on a topic — either explicitly or by telling Sherman to drop it — that idea is filtered out of future proposals. The system also tracks which topics I've told it to avoid entirely, as a standing list separate from individual rejections.
I'm not going to get into the specifics of how the matching works because there are some evasion-risk details I'd rather not publish. But the functional result is: a dead idea stays dead. The pitch queue each morning is genuinely new options, not a reshuffled version of yesterday's.
What this actually changes about how I work
The practical difference is that I start most mornings with a short list of pre-reasoned options instead of a blank page. Each pitch has a subject, a one-sentence argument for why it's worth doing right now, and a rough sense of how high-leverage it is. I can scan the list in two minutes and either pick one, add a note, or ask Sherman to explain the reasoning behind a specific pitch before I decide.
I still override the system constantly. Some mornings I have something specific I want to write and the pitch queue is irrelevant. Some mornings I look at all five pitches and none of them feel right and I ask for more. The queue is a starting point, not a mandate.
But here's what changed: I'm no longer starting from nothing. The cognitive work of "what should I even think about today" is mostly handled before I sit down. That's the part of content creation I find most draining — not the writing, but the cognitive work of deciding what's worth making. The pitch generator takes a real swing at that question every morning and leaves the final call to me.
The thing I keep coming back to
There's a version of AI-assisted content work where the system does as much as possible and you rubber-stamp it. I tried that version. It's faster in a narrow sense and it's also kind of hollow — you end up publishing things you didn't really choose, and eventually you can feel that in the work.
The pitch-first architecture is slower at the front end. There's a step I have to do every morning that the old system didn't require. But everything downstream of that approval feels like mine in a way the auto-drafted stuff didn't.
I think this is probably true for most people building AI-assisted workflows that actually feel good to work inside, not just content pipelines. The systems that feel good to work inside are usually the ones where the machine handles the legwork and you handle the decisions — not the ones where the machine handles everything and you just check for errors.
The next deep dive in this series gets into the research layer — what happens after a pitch gets approved, how Sherman actually goes and finds the material, and what I've had to constrain there to keep the outputs honest. If you haven't read the hub article that this series is built around, that's the right place to start — it covers the whole AI system behind this site and how all the pieces connect.